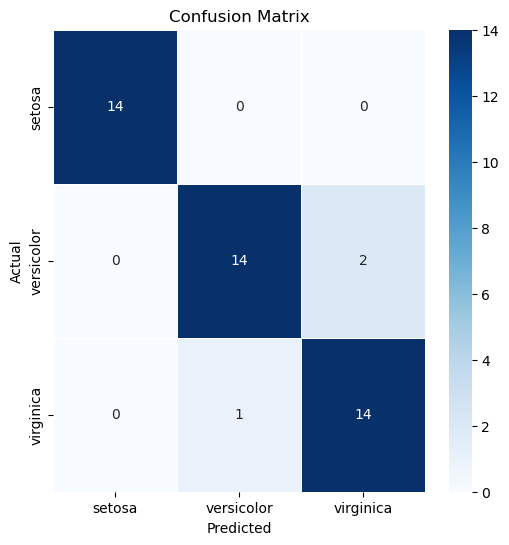
This notebook implements a neural network for classifying the Iris dataset using MLPClassifier from Scikit-Learn instead of manually programmed functions.
import numpy as npfrom sklearn.neural_network import MLPClassifierfrom sklearn.metrics import confusion_matrix, classification_reportimport seaborn as snsimport matplotlib.pyplot as pltimport pandas as pd# Load data from binary datasetdata = np.load("iris_train_test_data.npz")# Extract dataX_train, y_train, X_test, y_test = data["X_train"], data["y_train"], data["X_test"], data["y_test"]print("Dataset loaded successfully.")
Dataset loaded successfully.
Defining and Training the Neural Network
We will use MLPClassifier from Scikit-Learn, which is a multi-layer perceptron classifier.
Hidden Layer Size: We use one hidden layer with 5 neurons (hidden_layer_sizes=(5,)).
Activation Function: The hidden layer uses the sigmoid function (activation='logistic') and the output layer uses softmax.
Learning Rate: The learning rate is set to 0.01.
Batch Size: The batch size is set to 10.
Epochs (Max Iterations): The training will run for 1000 iterations (max_iter=1000).
Scikit-Learn automatically selects the appropriate loss function based on the type of classification problem. When using MLPClassifier, the behavior is as follows:
If MLPClassifier detects that the target variable (y_train) has more than two classes and is formatted in one-hot encoding, it automatically applies log_loss, which is equivalent to Softmax + Cross-Entropy loss.
For binary classification, the default loss is log-loss, applied to a sigmoid output layer.
For regression problems, MLPRegressor uses squared_loss (Mean Squared Error, MSE).