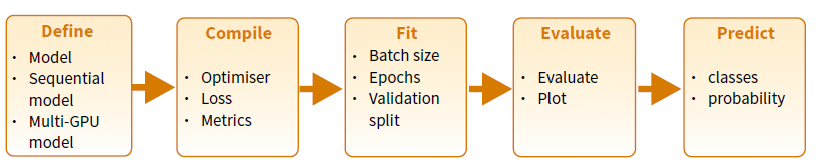
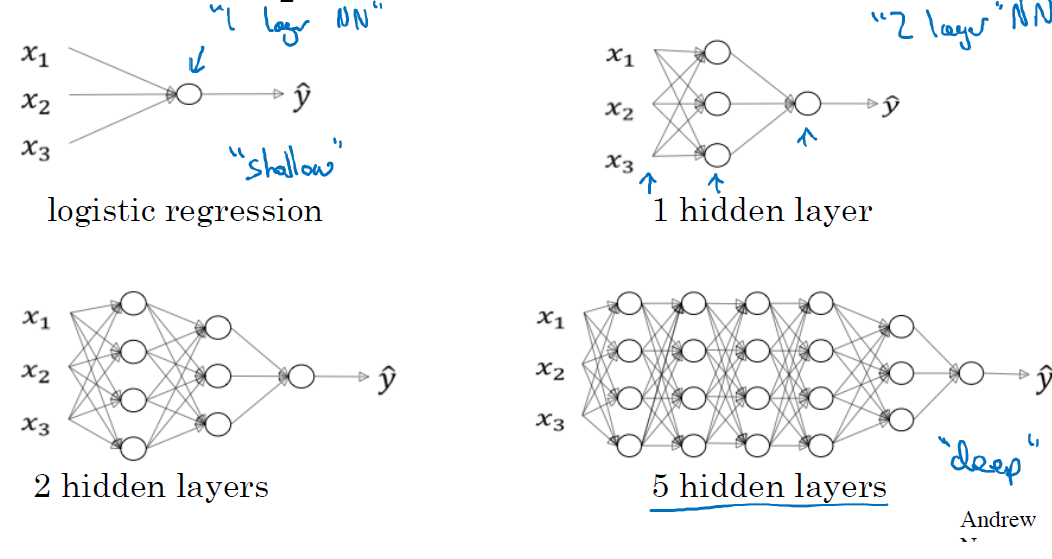
“Deep Neural networks” are NNs with several hidden layers.
Real shift from Shallow to DNNs did not (only) come arrive from noticing that newtorks with more layers were able to perform better, in spite of their huge number of parameters.
It mainly arrived by realizing that
While some tasks, such as digit recognition, could be solved decently well using a “brute force” approach,
Other, more complex, such as distinguishing a human face in an image, are hard to solve witht that “brute” force approach.
But can be solved using Deep Neural Networks
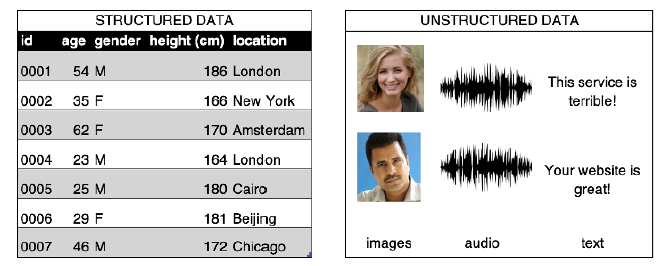
Structured-Unstructured data
Problems that can be better solved using DNNs are often associated with non-structured data.
‘Source: Generative Deep Learning. David Foster (Fig. 2.1)’
Images are unstructured data
Task: Distinguish human from non-human in an image
Source: ‘Neural Networkls and Deep Learning’ course, by Michael Nielsen
Example: Face recognition
Can be attacked similarly to the digit identification,
Cost of training would be much higher.
Alternatively: try to solve the problem hierarchically.
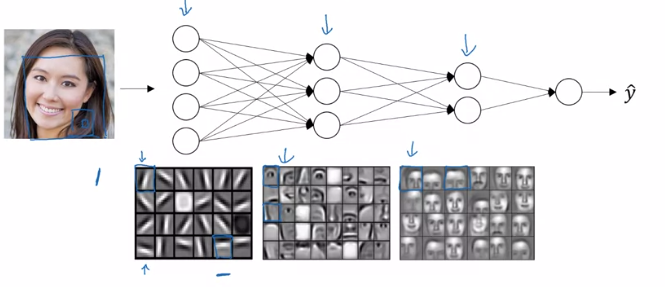
We start by trying to find edges in the figure
In the parts with edges look around to find face pieces, a nose, an eye, an eyebrow …
As pieces are located, look for their optimal combination.
A hierarchy of complexity
Source: ‘Deep Learning’ course, by Andrew Ng in Coursera & deeplearning.ai
A hierarchy of complexity
Each layer has a more complex task, but it receives better information.
If we can solve the sub-problems using ANNs,
We may be able to combine those NNs into a bigger network to solve the problem, here face-detection.
Deep Neural Networks
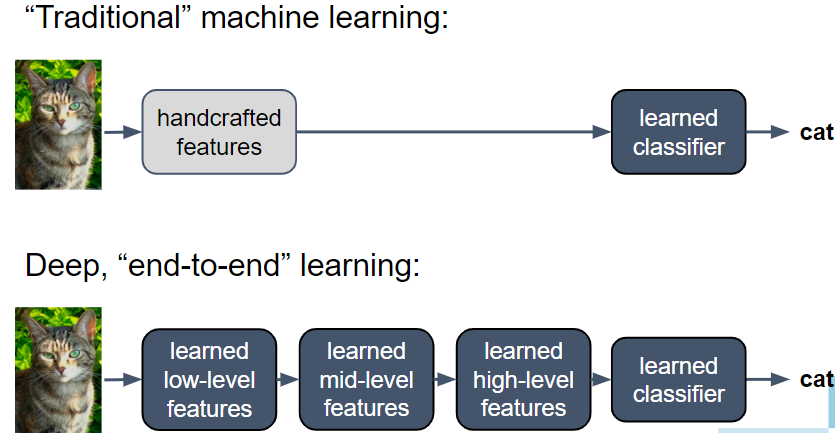
Neural Networks with such structure are called Deep Neural Networks and are characterized by
building progressively, from simple to complex structures,
learning increasingly abstract representations at each layer and
The success of Deep Neural Networks (DNNs) is largely due to their ability to automatically learn and adjust the complex hierarchy of representations, without requiring handcrafted feature extraction or manual tuning of weights and biases.
Shift from manual feature engineering to automatic tuning enabled by new or improved techniques such as:
Stochastic Gradient Descent (SGD) and Backpropagation: Allow learning optimal parameters through iterative updates.
Better Weight Initialization (e.g., Xavier/He initialization): Improve convergence and training stability.
Source: ‘Deep Learning’ course, by Andrew Ng in Coursera & deeplearning.ai
Deep Learning Architectures
The hierarchical approach to solve complex problems -especially with unstructured data- leads to the development of diverse deep learning architectures, each designed to tackle specific challenges.
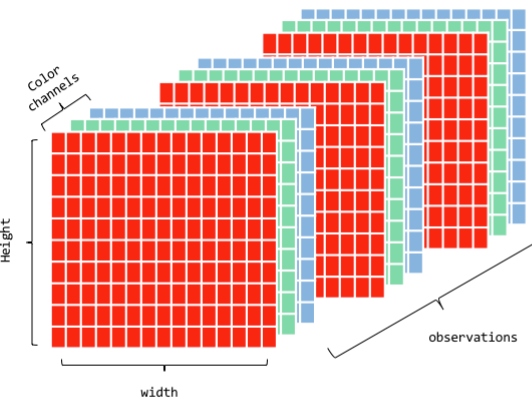
Convolutional Neural Networks (CNNs) for image and spatial data processing.
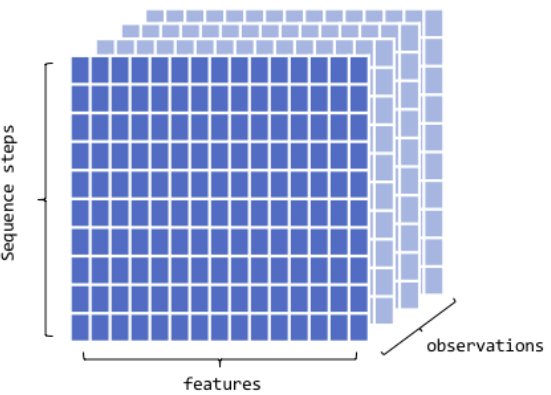
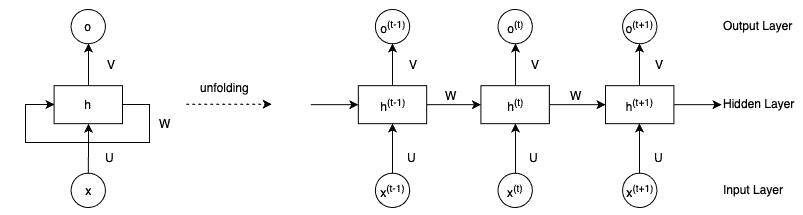
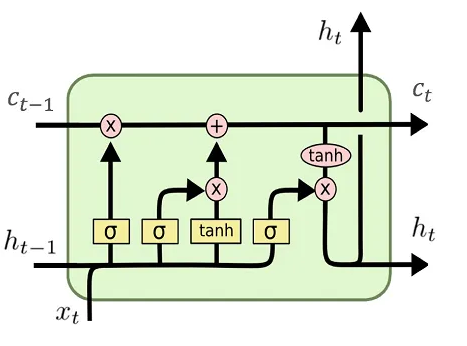
Recurrent Neural Networks (RNNs) & Transformers for sequential data: time series, natural language processing.
Autoencoders & Variational Autoencoders (VAEs): for unsupervised learning, anomaly detection, and data compression.
Generative Adversarial Networks (GANs) For generating realistic synthetic data including: images, text, and audio.
Graph Neural Networks (GNNs): to process relational and structured data, such as social networks and molecular structures.
Convolutional Neural Networks
CNNs are specialized for processing grid-like data, such as images.
They use convolutional layers to detect spatial hierarchies in data.
Transformers revolutionized deep learning by replacing sequential processing with self-attention mechanisms.
Self-attention allows the model to weigh the importance of different input tokens when making predictions.
It can capture long-range dependencies without the need for sequential processing.
Primary use: Natural Language Processing (NLP) & Large-scale sequence modeling.
Transformer Architecture
Models & Applications
Models: BERT, GPT, T5, Transformer-XL.
Applications:
Chatbots (ChatGPT, Bard, Bing AI).
Automated text summarization.
Machine translation (Google Translate, DeepL).
Code generation and AI-assisted programming.
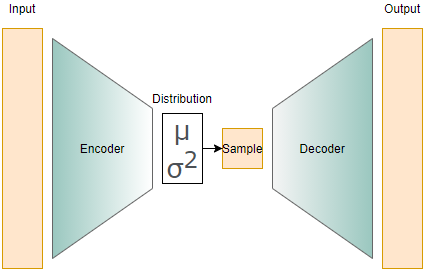
Autoencoders & Variational AEs
Autoencoders learn to compress and reconstruct data by reducing input dimensionality and mapping it to a latent vector that represents essential features.
VAEs introduce probabilistic modeling, generating latent representations that allow for controlled data synthesis.
Unlike traditional autoencoders, VAEs do not map data to a fixed latent vector but to a probability distribution
This enables smoother interpolations and diverse outputs.
Primary use: Dimensionality reduction, anomaly detection, and generative modeling.
VAEs particularly useful in generative tasks, such as creating synthetic images or text.



 Source: From RNNs to Transformers
Source: From RNNs to Transformers