Advanced Machine Learning
Neural Networks, Deep Learning
and Artificial Intelligence
Historical Background (1)
In the post-pandemic world, a lightning rise of AI, with a mess of realities and promises is impacting society.
Since ChatGPT entered the scene everybody has an experience, an opinion, or a fear on the topic.

The early history of AI (1)
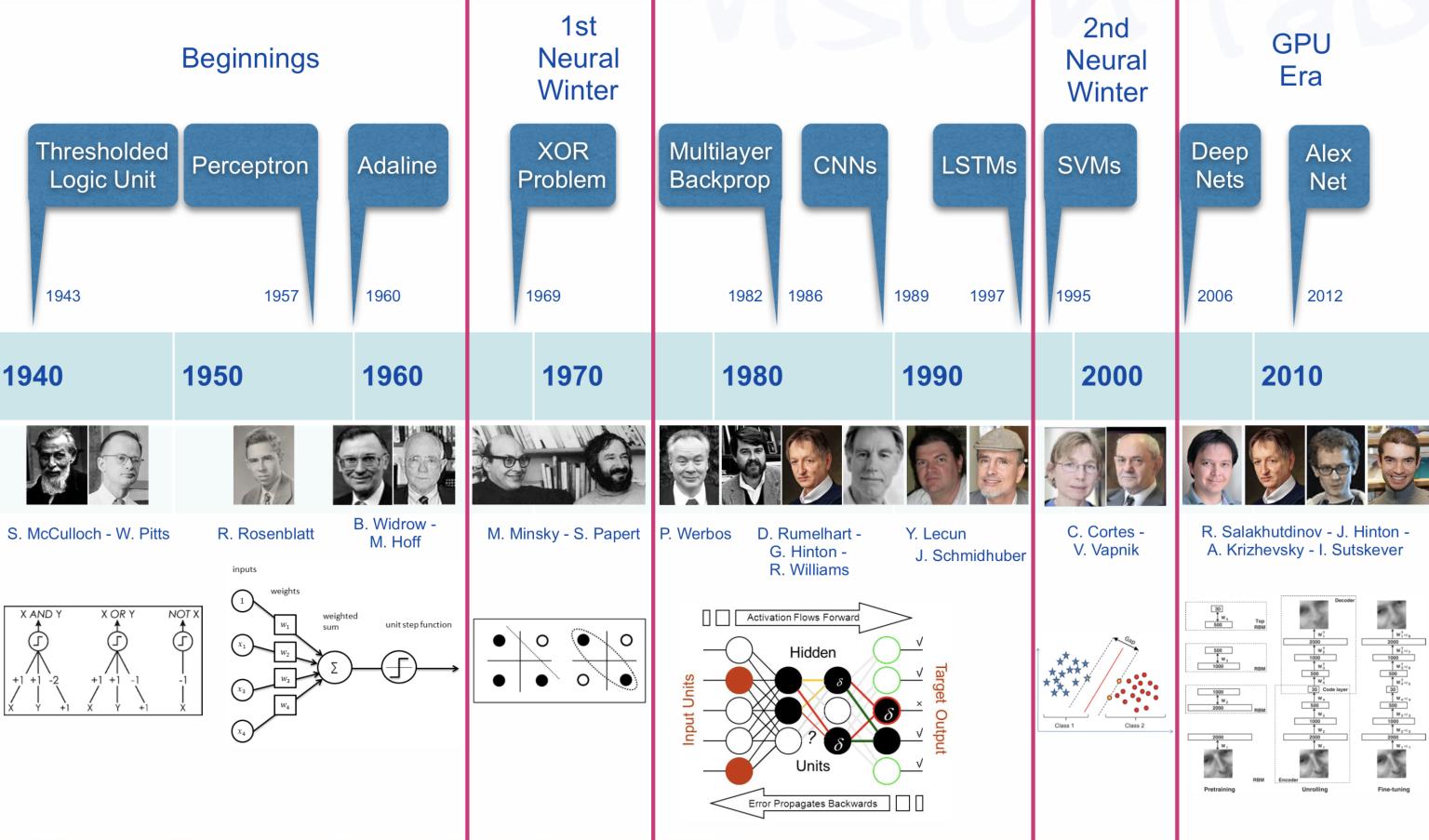
From ANN to Deep learning

Why Deep Learning Now?
Not to talk abou the fears
AI also comes with fears from multiple sources from science fiction to religion
Mass unemployment
Loss of privacity
AI bias
AI fakes
Or, simply, AI takeover

Back to science
Where/How does it all fit?
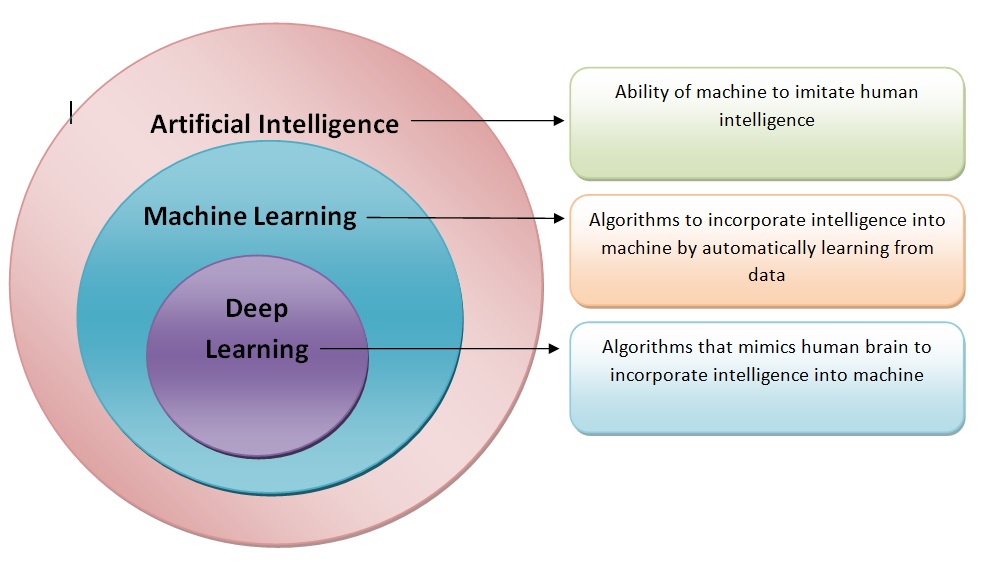
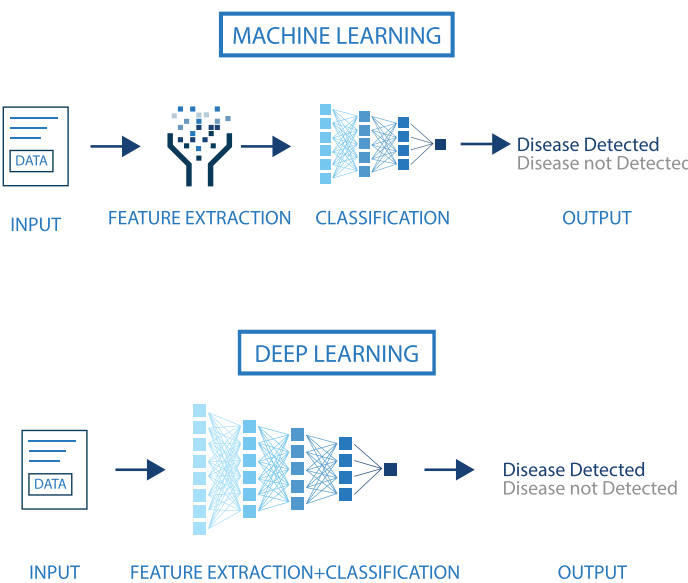
How does DL improve
Size does matter!
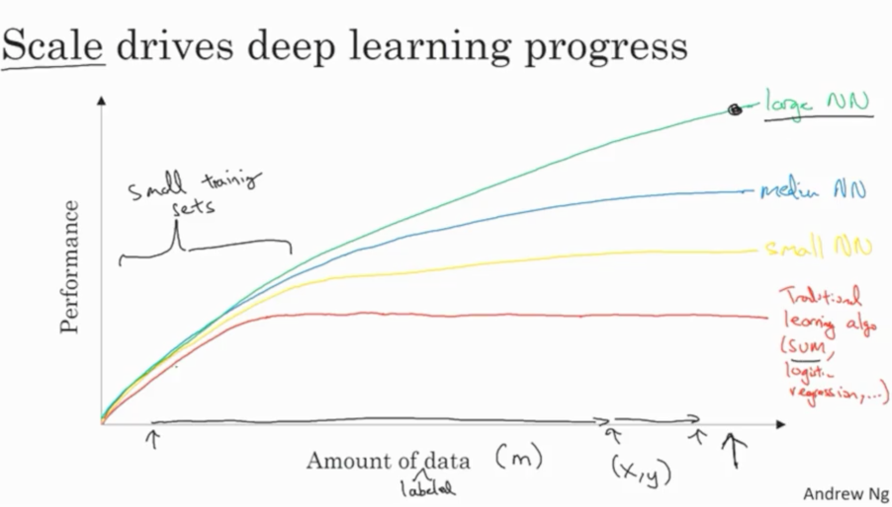
An illustration of the performance comparison between deep learning (DL) and other machine learning (ML) algorithms, where DL modeling from large amounts of data can increase the performance
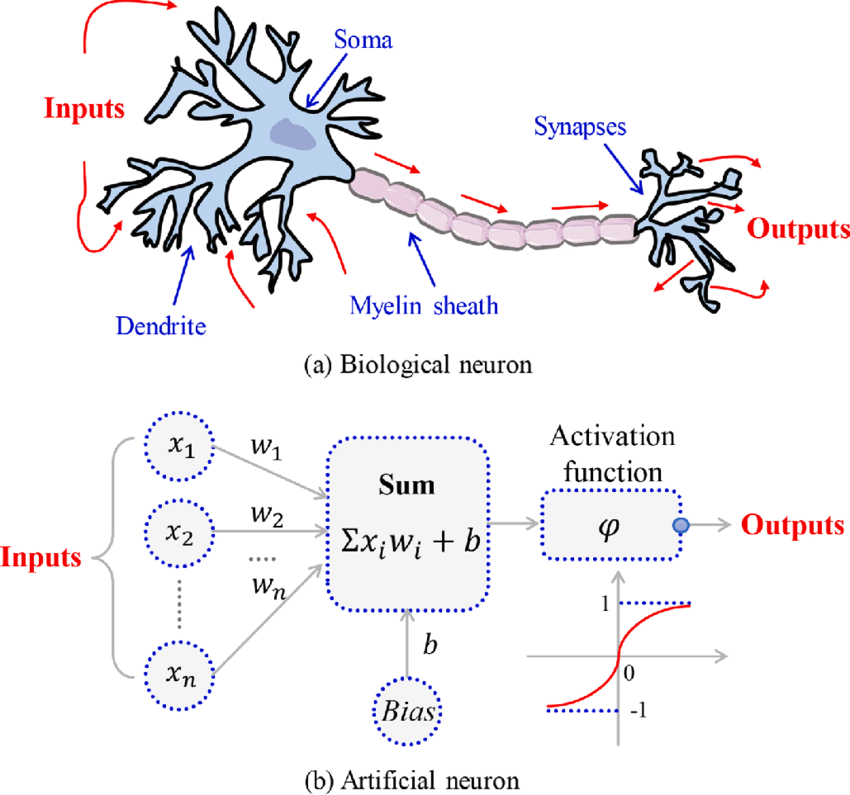
Emulating biological neurons
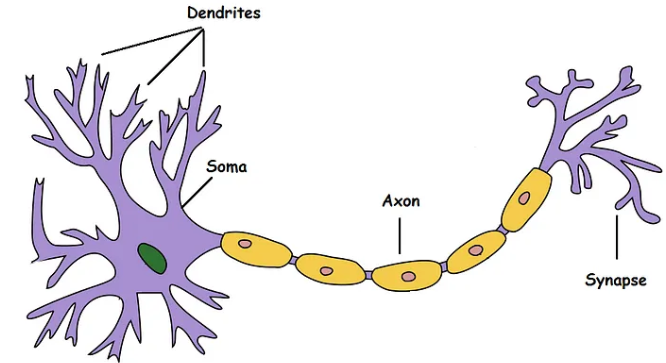
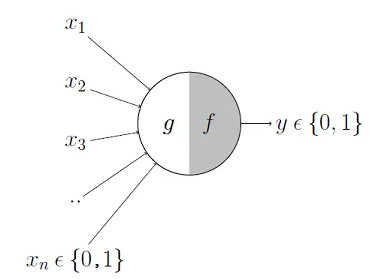
- The first model of an artifial neurone was proposed by Mc Cullough & Pitts in 1943
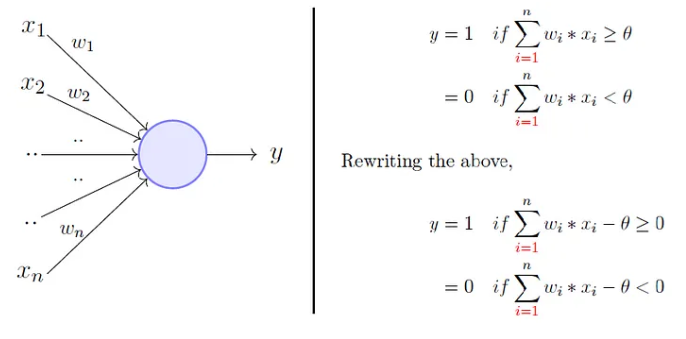
Rosenblatt’s perceptron
Activation function
The sigmoid function
\[ f(z)=\frac{1}{1+e^{-z}} \]
Output real values \(\in (0,1)\).
Natural interpretations as probability

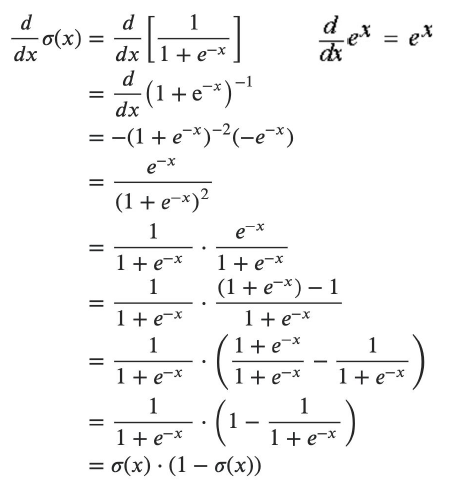
the hyperbolic tangent
Also called tanh, function:
\[ f(z)=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}} \]
outputs are zero-centered and bounded in −1,1
scaled and shifted Sigmoid
stronger gradient but still has vanishing gradient problem
Its derivative is \(f'(z)=1-(f(z))^2\).
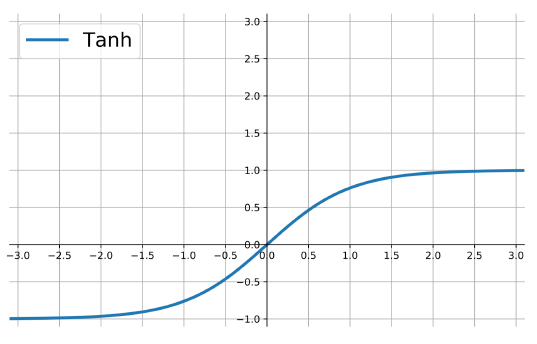
The ReLU
rectified linear unit: \(f(z)=\max\{0,z\}\).
Close to a linear: piece-wise linear function with two linear pieces.
Outputs are in %(0,)$ , thus not bounded
Half rectified: activation threshold at 0
No vanishing gradient problem
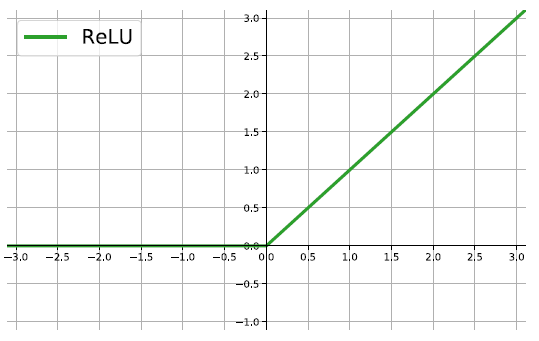
More activation functions
 .
.
Putting it all together
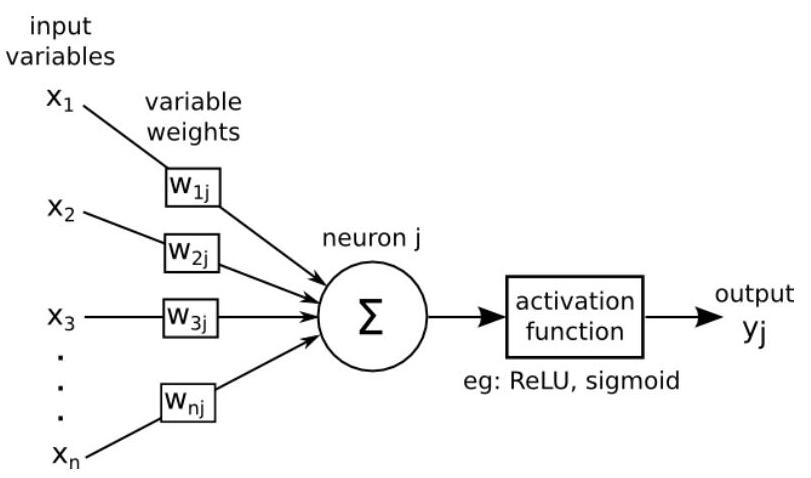
An Artificial Neural network
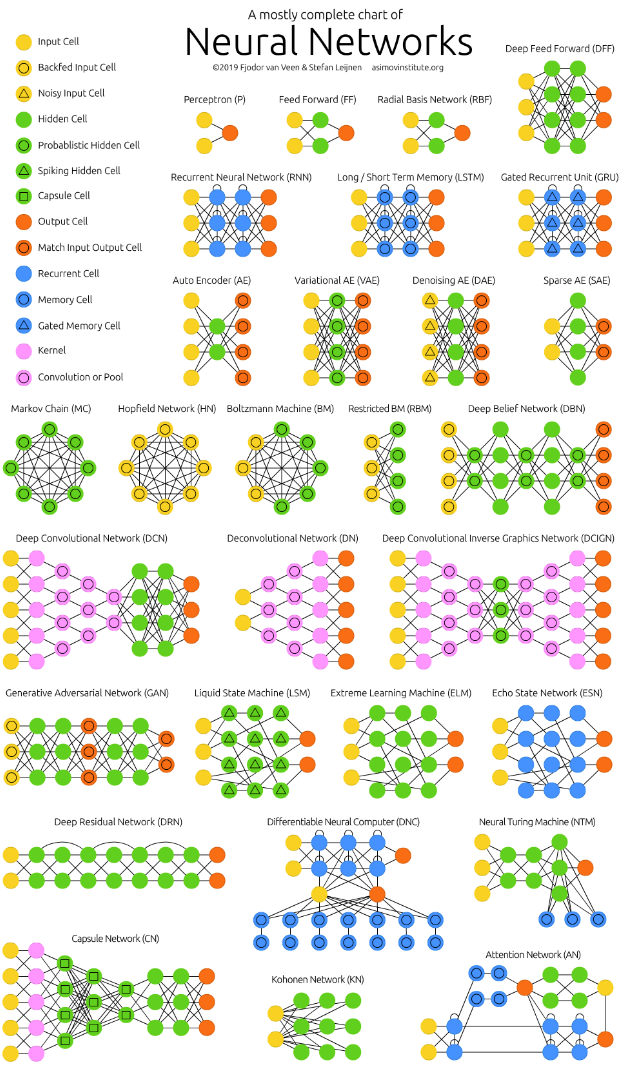
Multiple architectures for ANN
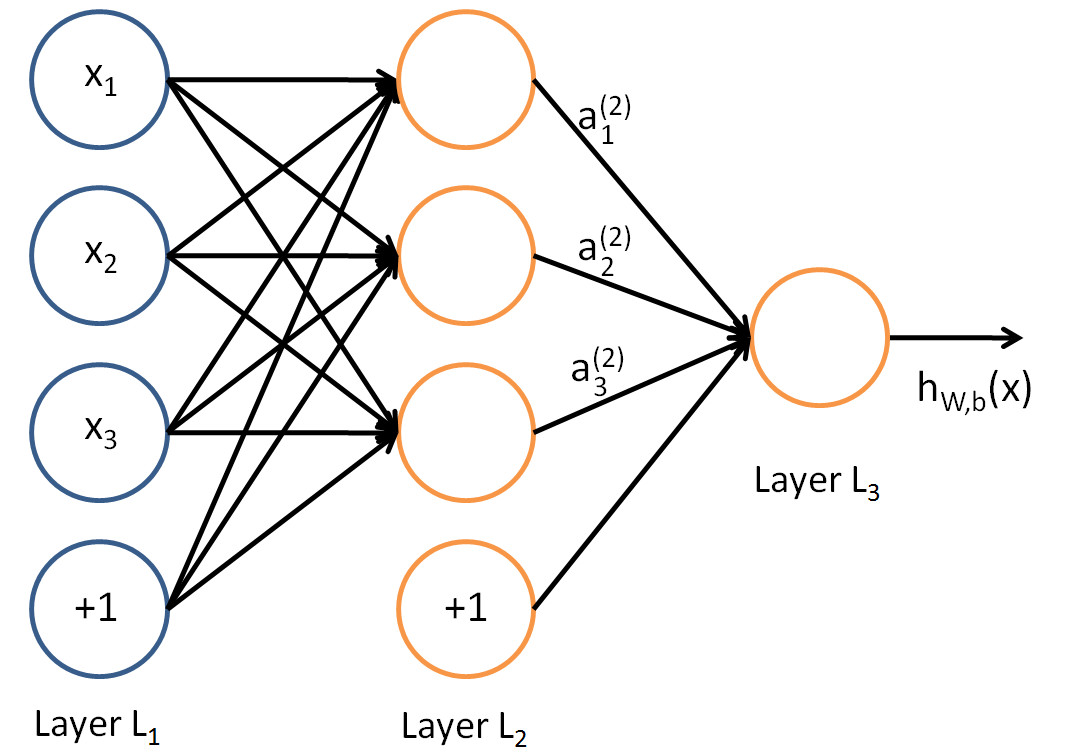
We have so far focused on a single hidden layer neural network of the example
One can build neural networks with many distinct architectures (meaning patterns of connectivity between neurons), including ones with multiple hidden layers.
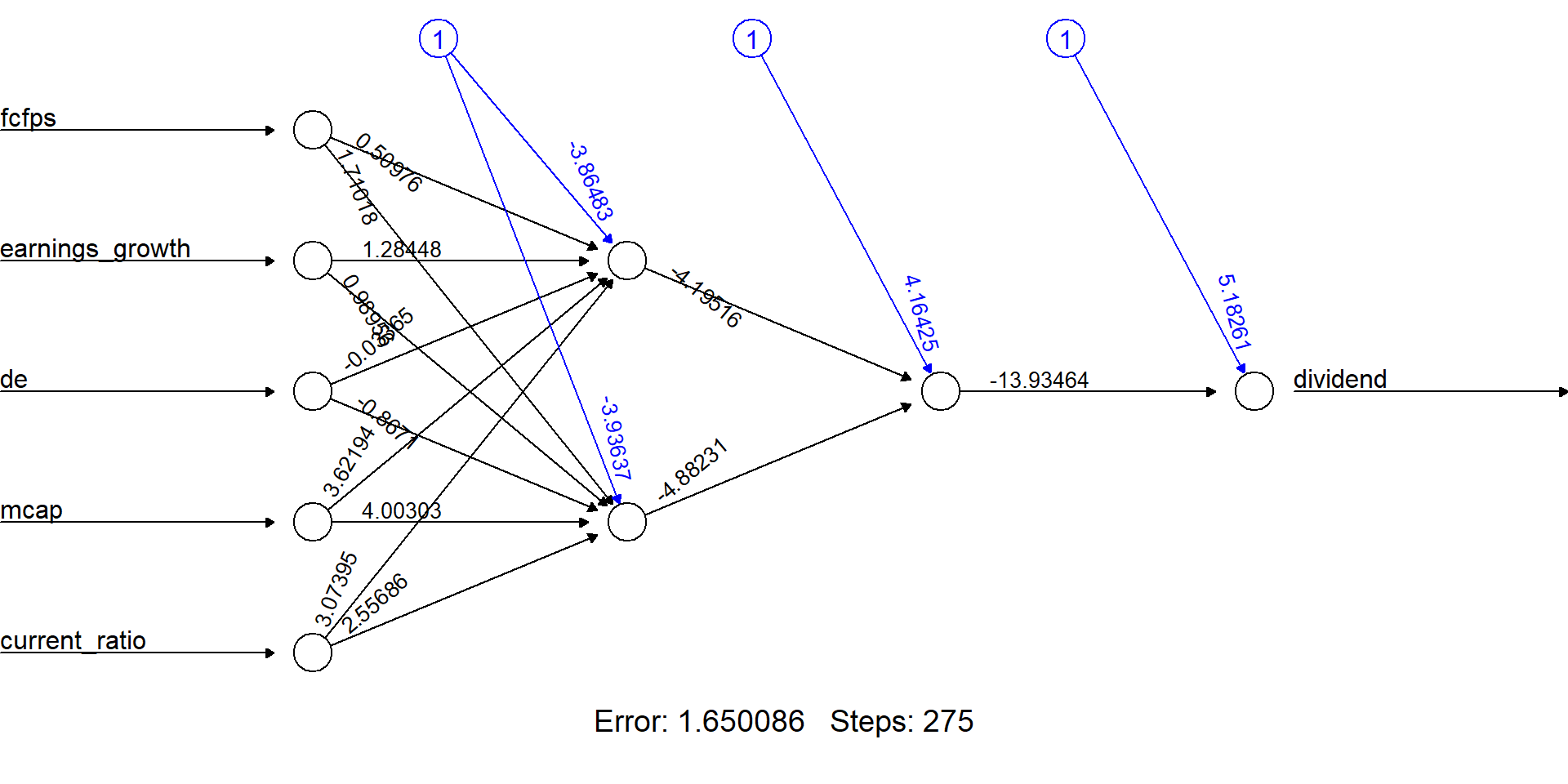
Network plot
The output of the procedure is a neural network with estimated weights
Deep Neural Networks
- Neural Networks may have distinct levels of complexity.
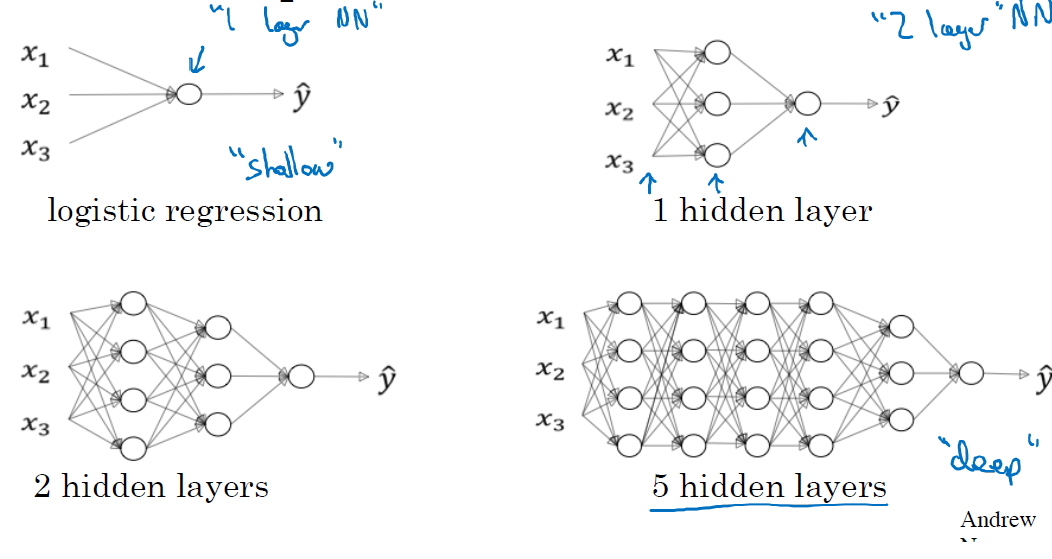
Source: ‘Deep Learning’ course, by Andrew Ng in Coursera & deeplearning.ai
Structured-Unstructured data
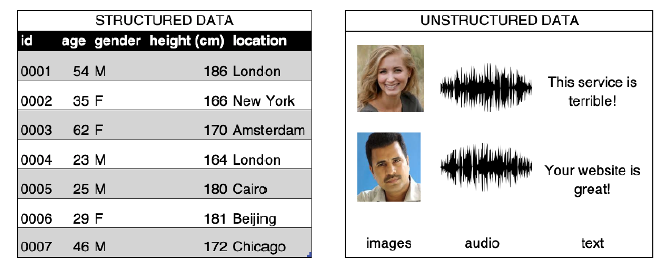
‘Source: Generative Deep Learning. David Foster (Fig. 2.1)’
Images are unstructured data
Task: Distinguish human from non-human in an image

Source: ‘Neural Networkls and Deep Learning’ course, by Michael Nielsen
A hierarchy of complexity
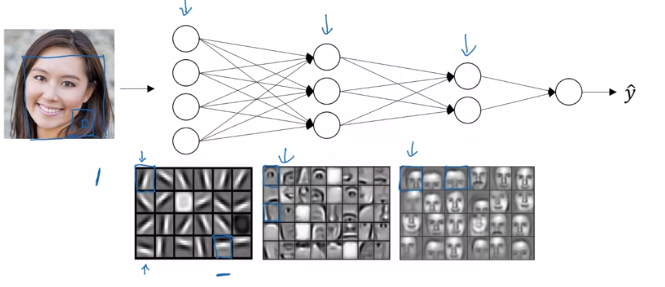
Source: ‘Deep Learning’ course, by Andrew Ng in Coursera & deeplearning.ai
Shallow vs Deep NNs
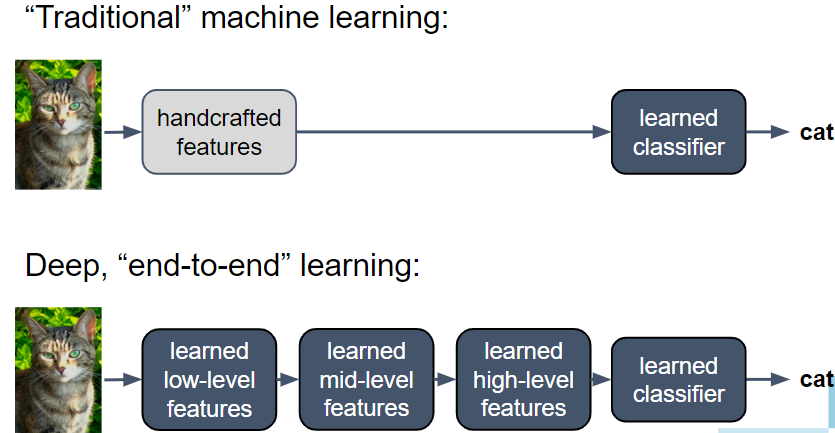
Source: ‘Deep Learning’ course, by Andrew Ng in Coursera & deeplearning.ai