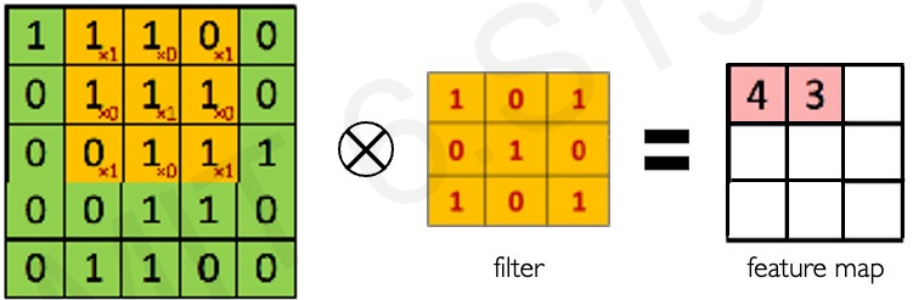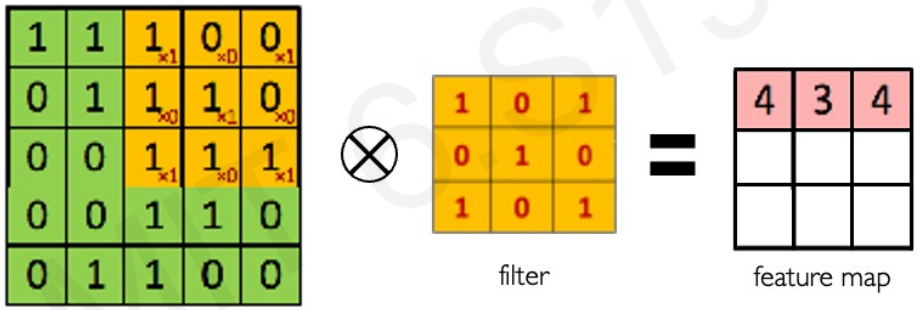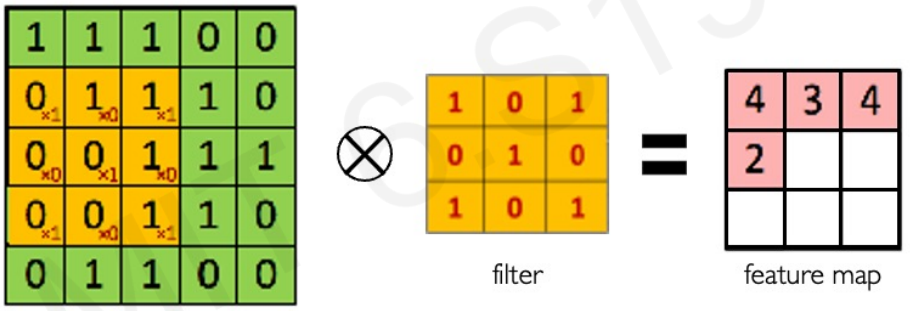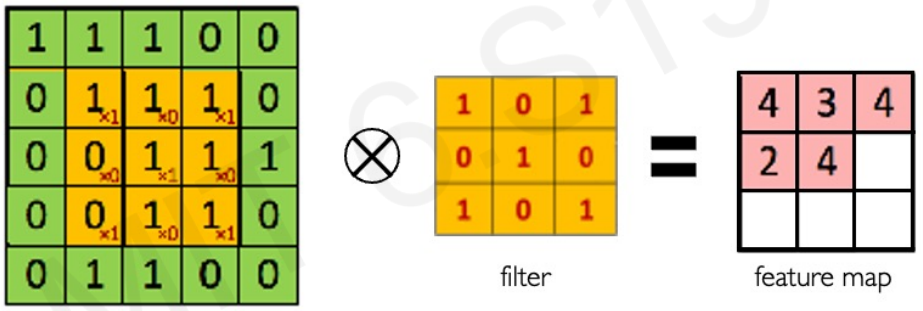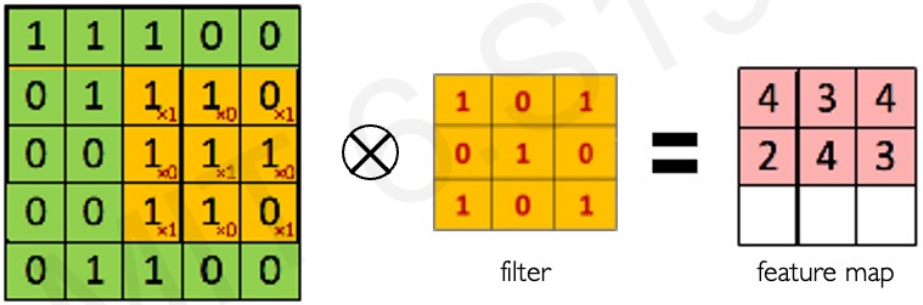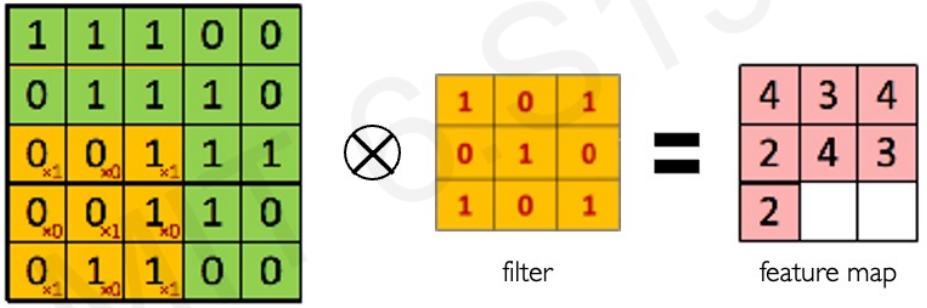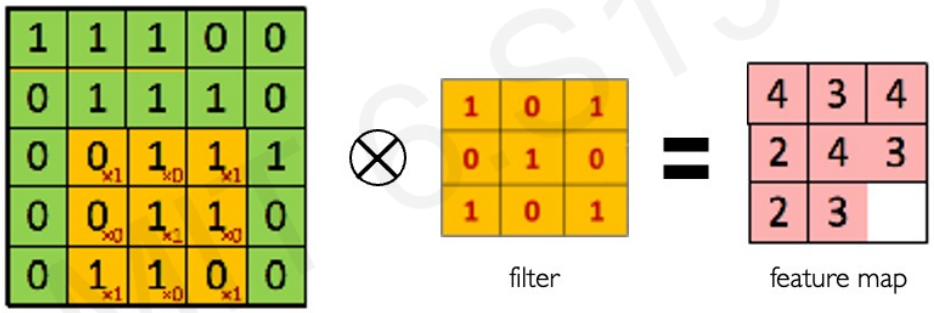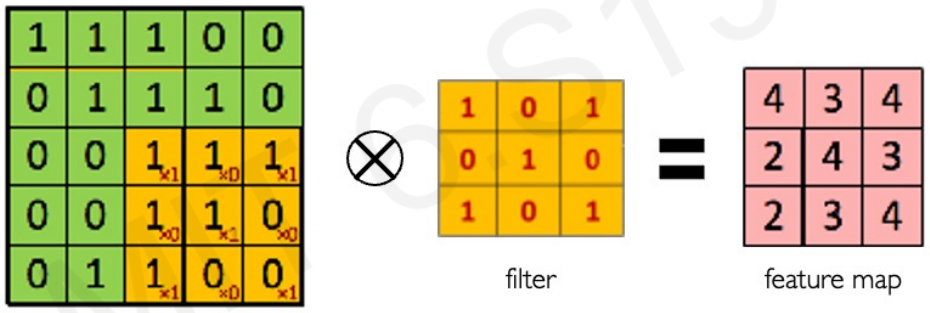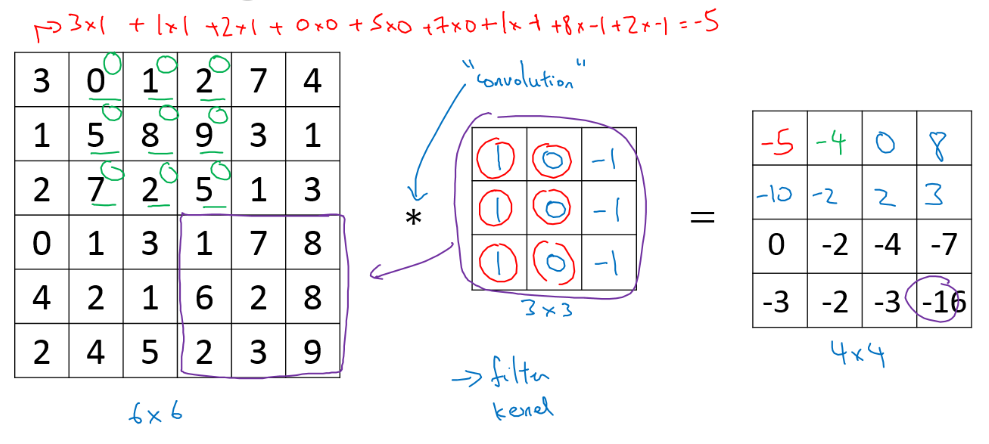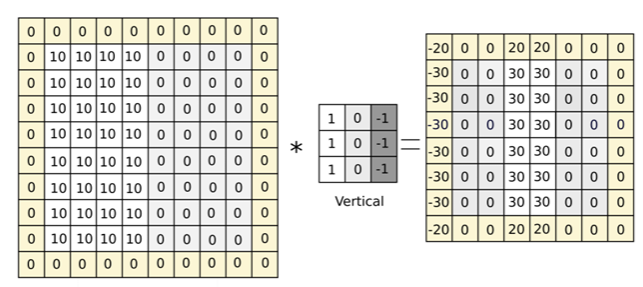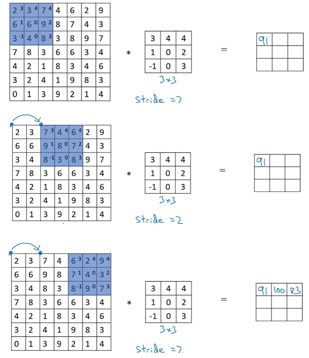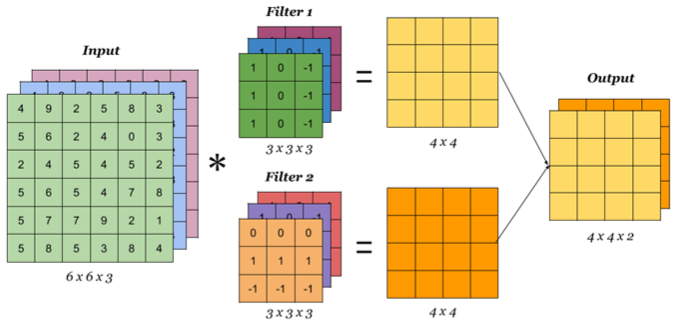
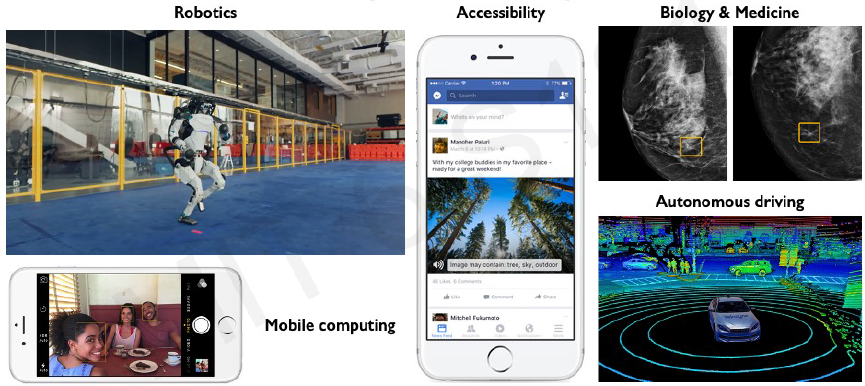


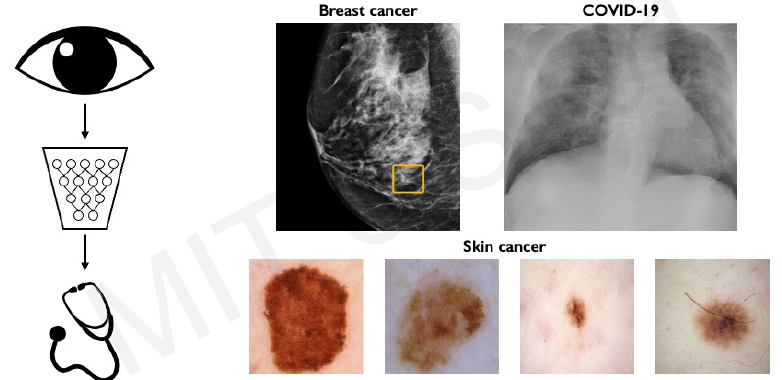




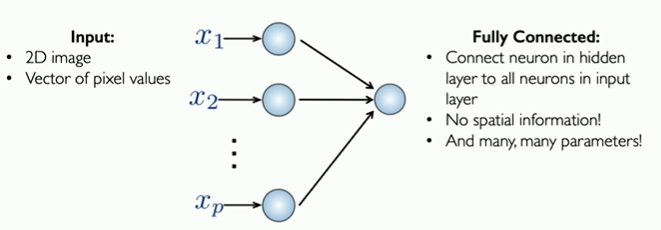
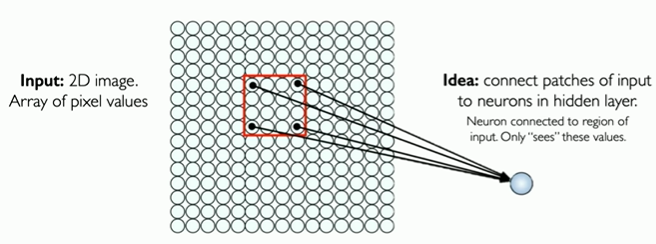
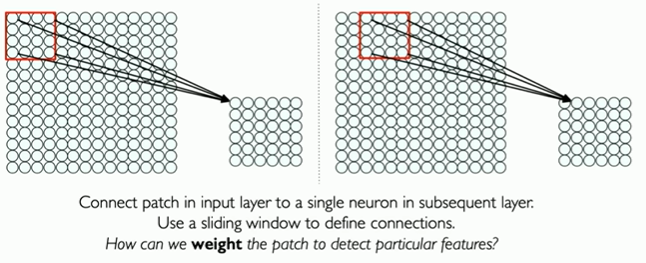


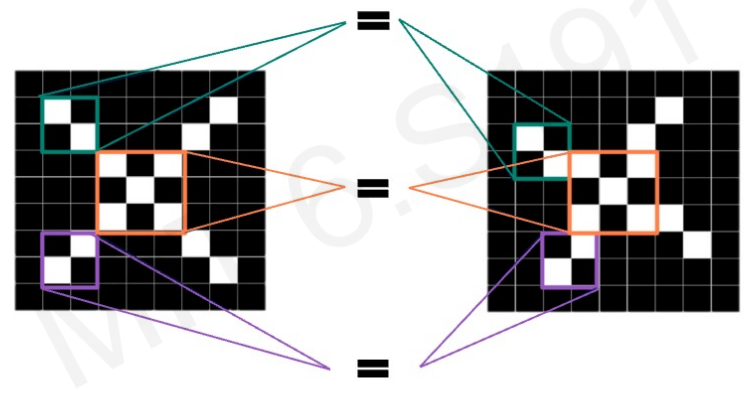
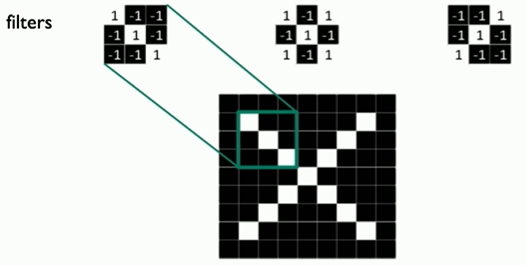
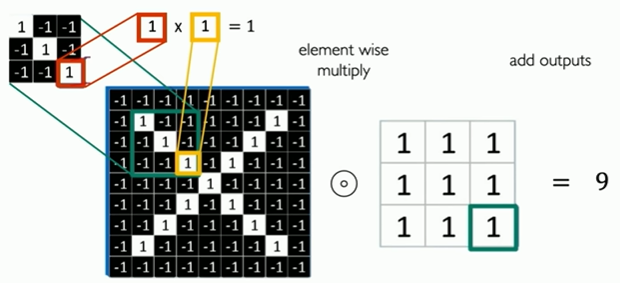
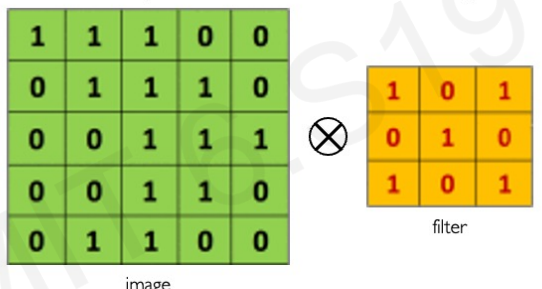
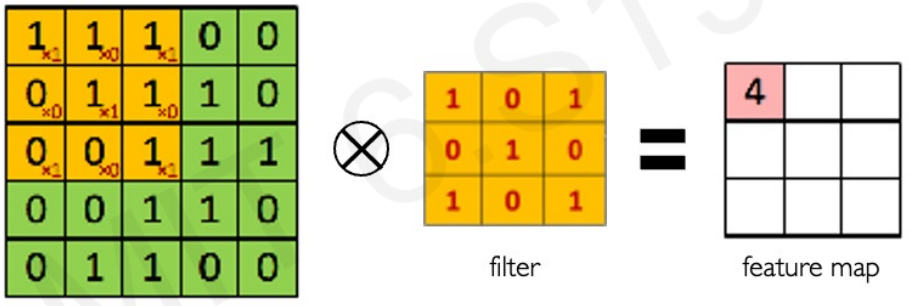
Main tasks in Computer Vision:
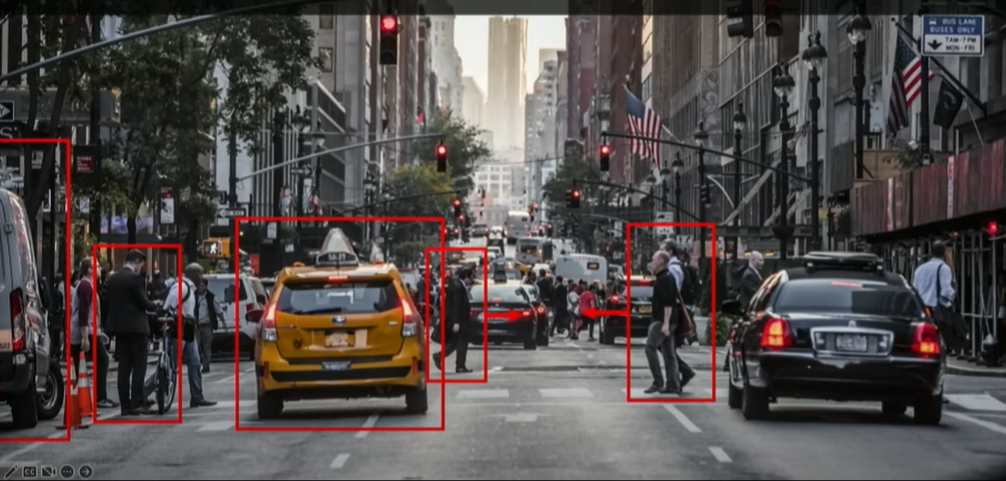
- Regression: Output variable takes continuous value. E.g. Distance to target
- Classification: Output variable takes class labels. E.g. Probability of belonging to a class
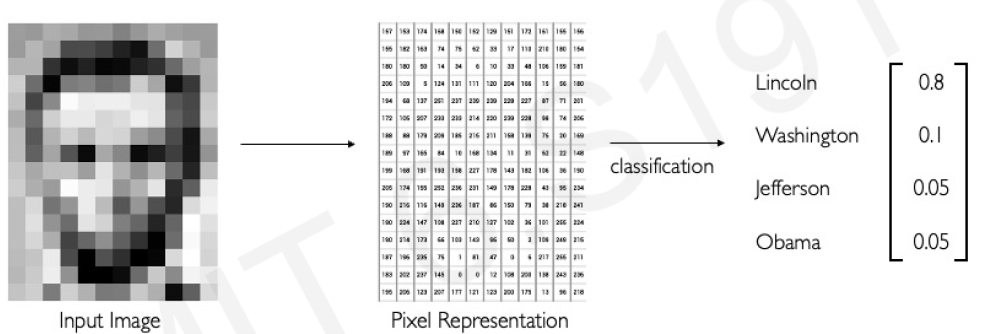
source: MIT Course, http://introtodeeplearning.com/, L3