Metabolites
1 Quinolinate
2 Glucose
3 3-Hydroxyisovalerate
4 Leucine
5 Succinate
6 Valine
7 N,N-Dimethylglycine
8 Adipate
9 myo-Inositol
10 Acetate
11 Glutamine
12 CreatinePathway Analysis for metabolomics
Introducing myself

Introducing Our groups

Statistics & Bioinformatics and Nutrition & Metabolomics groups @ UB
Health, Disease and Pathways
Metabolism is a complex network of chemical reactions within the confines of a cell that can be analyzed in self-contained parts called pathways.
We often assume that “normal” metabolism is what happens in healthy state or, that disease can be associated with some type of alteration in metabolism.
Characterization of disease attempted studying how ths disrupts pathways
Bioinformatics workflows
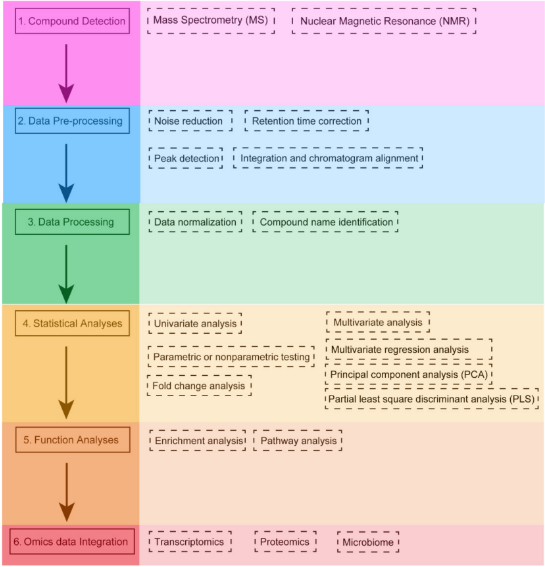
From samples to features lists (2)
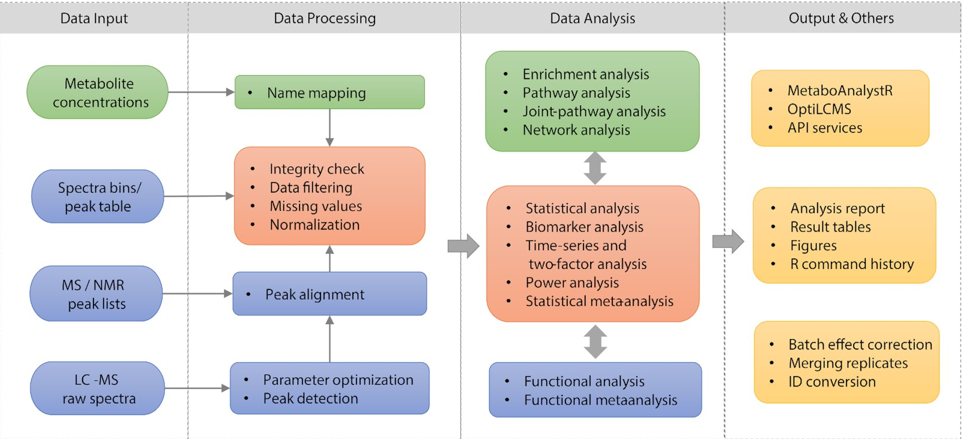
Metabolomics Workflows in MetaboAnalyst 5.0
Analysis yields metabolites lists
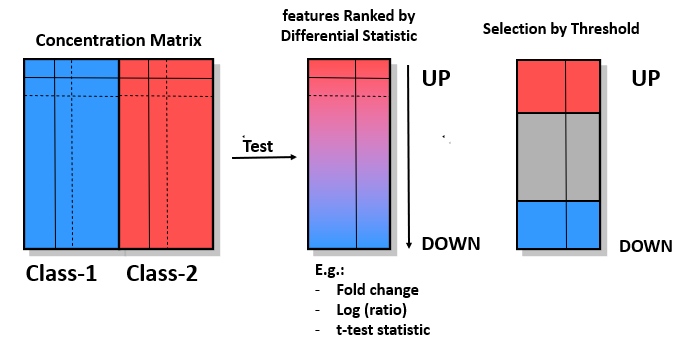
- A typical analysis can result in diverse types of metabolite lists:
Top 10 most different metabolites in the Cachexia dataset
- Truncated
- Unordered
- Only has metabolite IDs
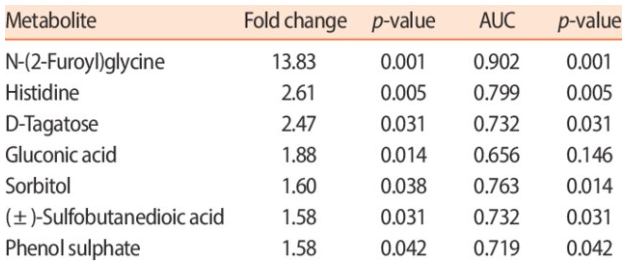
- All the features analyzed
- Ordered or ranked
- IDs and effect size measures
Many sources for names

Some compund databases
Computed descriptors for Cholesterol

Computed descriptors for Cholesterol
Many synonyms

Other names for Cholesterol
The where to, now? question
Once a list of feature is obtained it can be studied on a one-by-one basis
Select some features for biochemical validation,
Map individual features to specific pathways,
Perform functional assays,
Do a literature search …
This will yield useful information, but
- It may be slow and resource-consuming
- It does not account for interaction between features.
How can we interpret these lists?
From Lists to Biology
Sources of information for PWA

Some common databases in Metabolomics
The Human Metabolome DB

- Detailed information about human metabolites, their structures, pathways, origins, concentrations, functions and reference spectra
- HMDB has 248,855 metabolites, 132,335 pathways, 3.1 million MS and NMR spectra, metabolite biomarker data on >600 diseases
- A resource established to provide reference metabolite values for human disease, human exposures & population health
- Captures both targeted and untargeted metabolomics (and exposomics) data
The Food Constituent Database
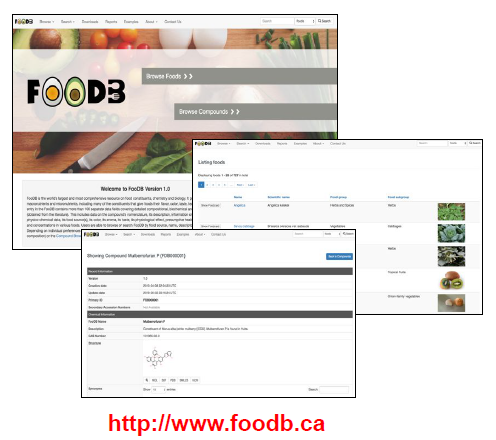
- Database of 70,000+ compounds found in 727 foods and their effects on flavour, aroma, colour and human health
- Comprehensive concentration information to ID foods that are rich in particular micronutrients
- Links chemistry to food types (biological species) to flavour, aroma, colour and human health
- Supports sequence, spectral, structure and text searches
The KEGG DB
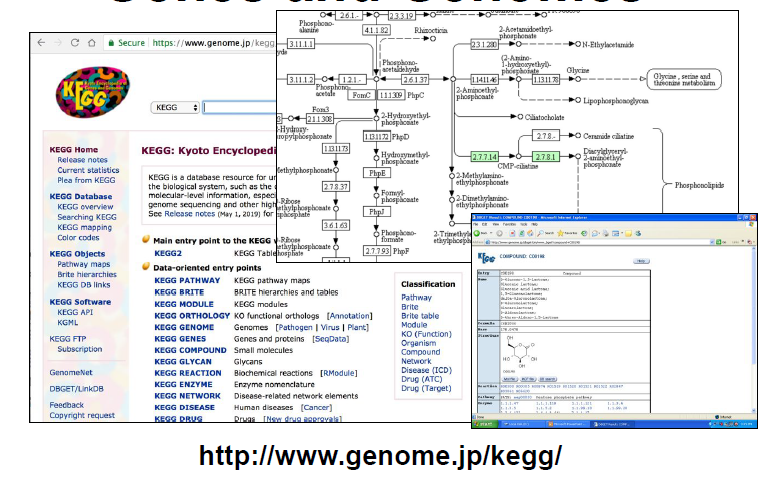
- The “Go-to” Metabolic Pathway Database
- Has 535 “canonical” pathway diagrams or maps covering 5994 organisms for a total of 604,808 pathways
- ~170 metabolic pathways covering 18,553 compounds, includes many disease pathways (80), protein signaling (70) pathways, and biological process pathways (70)
- Metabolic pathways are highly schematized and mostly limited to catabolic and anabolic processes
Small Molecule Pathway Database
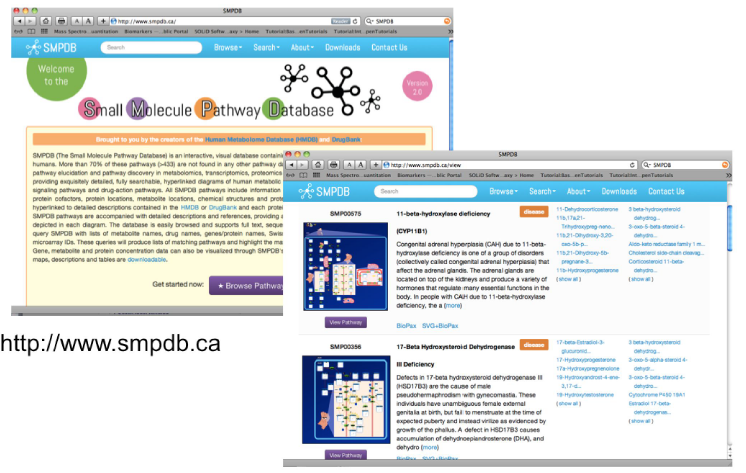
Nearly 48,900 hand-drawn small molecule pathways – 404 drug action pathways – 20,251 metabolic disease pathways – 27,876 metabolic pathways – 160+ signaling and other pathways
Depicts organs, cell compartments, organelles, protein locations, and protein quaternary structures
Maps gene chip & metabolomic data
Converts gene, protein or chemical lists to pathways or disease diagnoses
PWA and Metabolite Sets

Chemical Ontologies
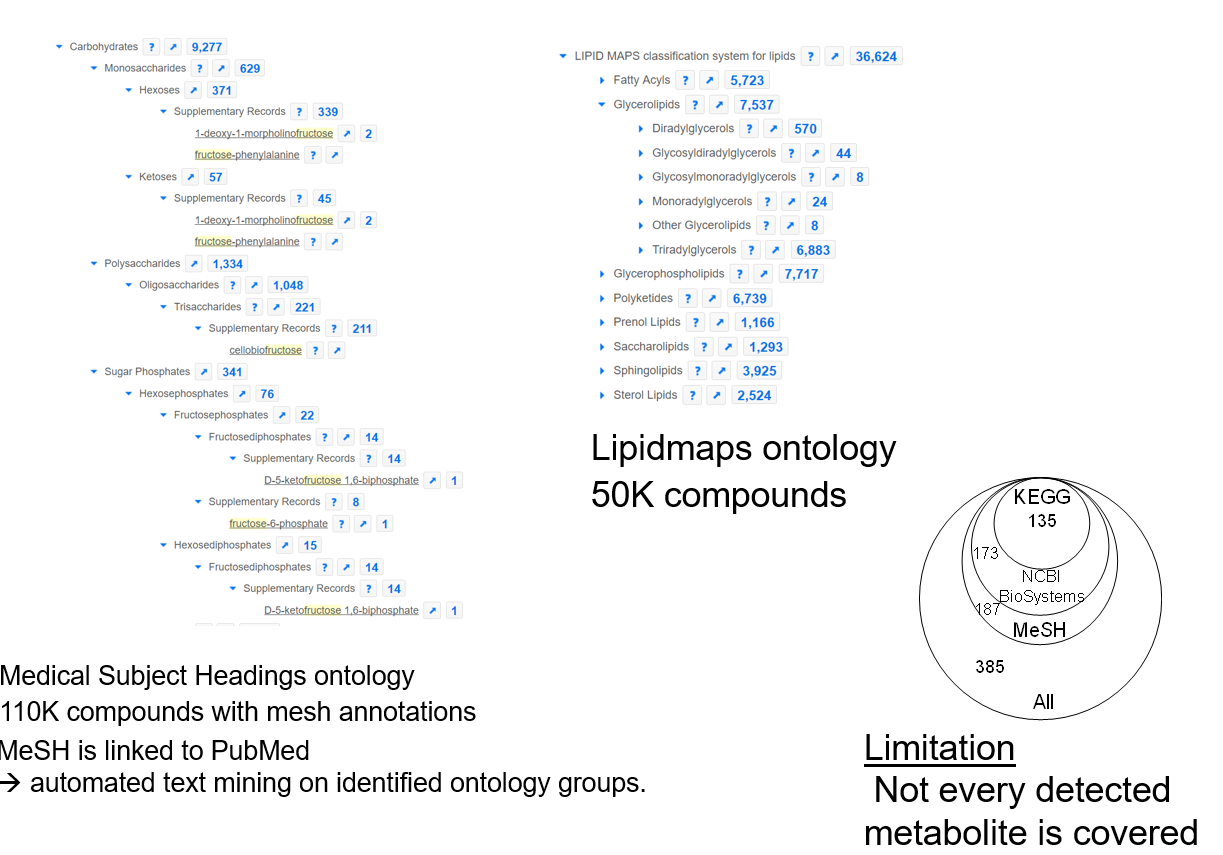
Metabolites Set libraries

Overview of MSEA’s metabolite set libraries
Metamap clusters
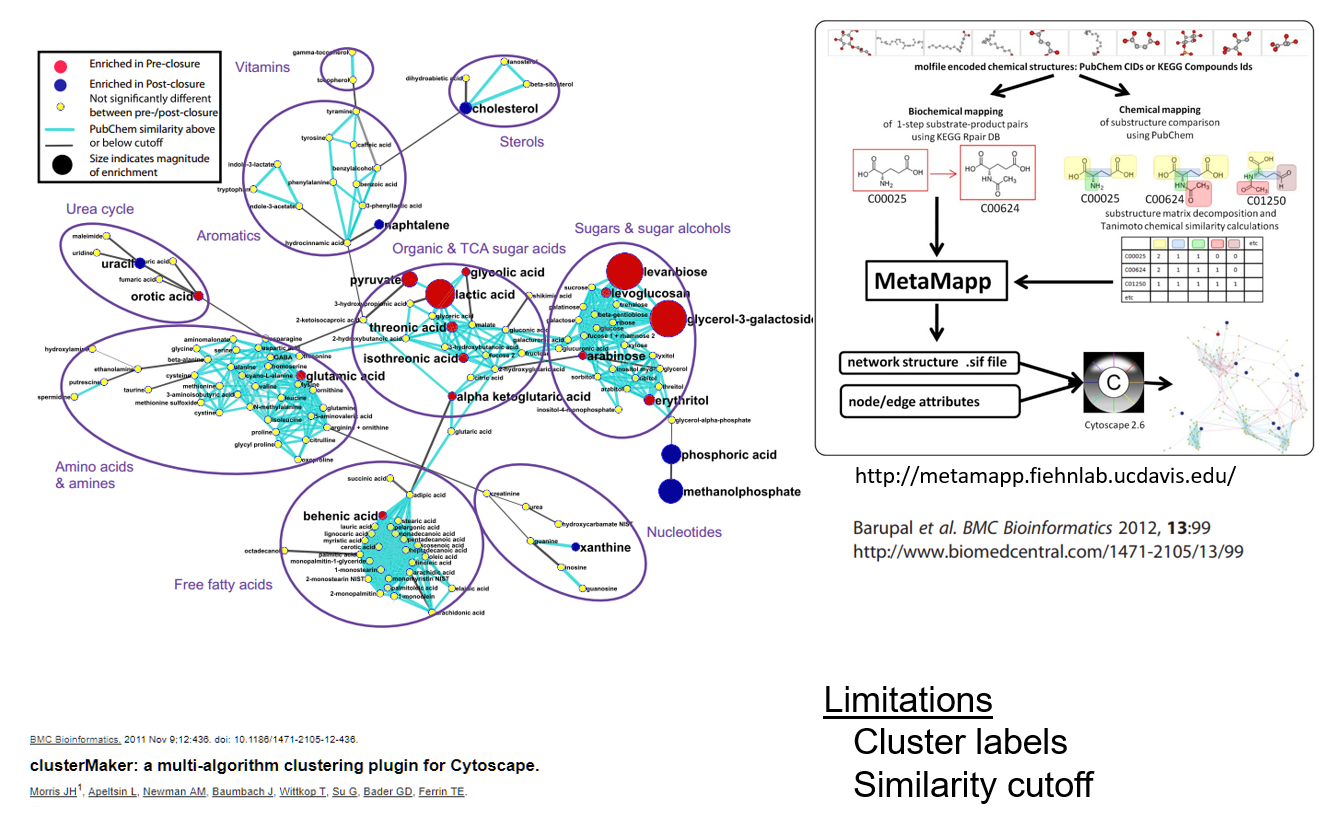
Chemical similarity clusters
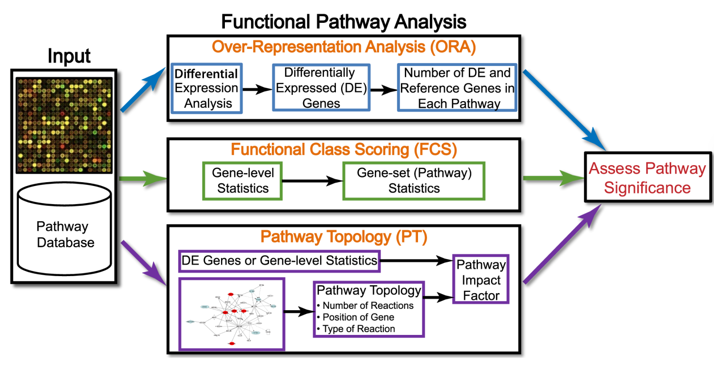
Types of Pathway Analysis
Obtaining feature lists
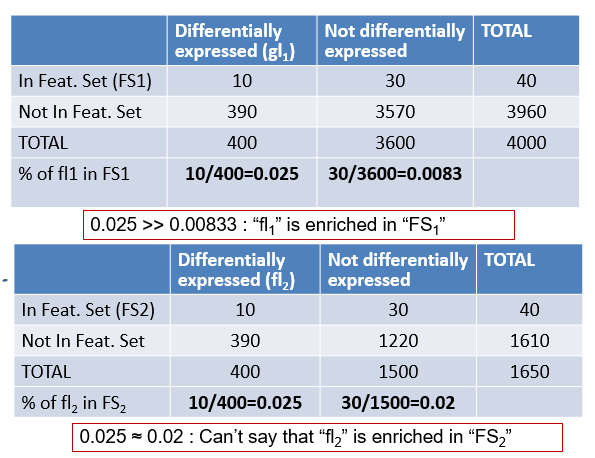
Assessing “surprisingly”
Given a feature list, “fl”, and a feature set, “FS”, check if the % of genes in “fl” annotated in “FS” the same as the % of genes globally annotated in “FS”?
- If both percentages are similar \(\rightarrow\) No Enrichment.
- If the % of features in “FS” is greater in “fl” than in the rest of genes \(\rightarrow\) “fl” is enriched in “GS”

Example
Example 1: Surprisingly enriched

P-value small, odds-ratio high: List is surprisingly enriched in Feature Set
Example 2: Non-enriched
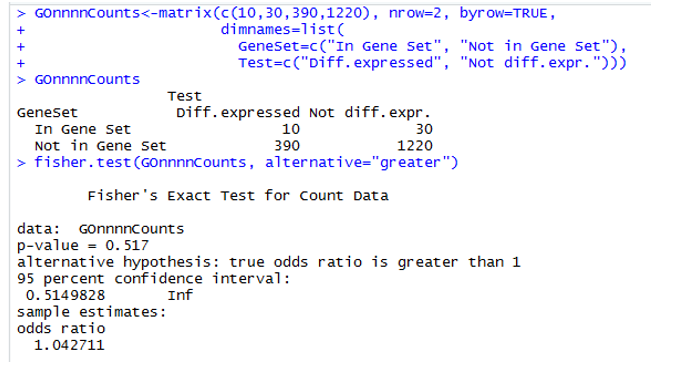
P-value high, odds-ratio around 1: List is not enriched in Feature Set
Functional Class Scoring
Also known as:
Analysis of ranked lists
Metabolite Set Enrichment Analysis
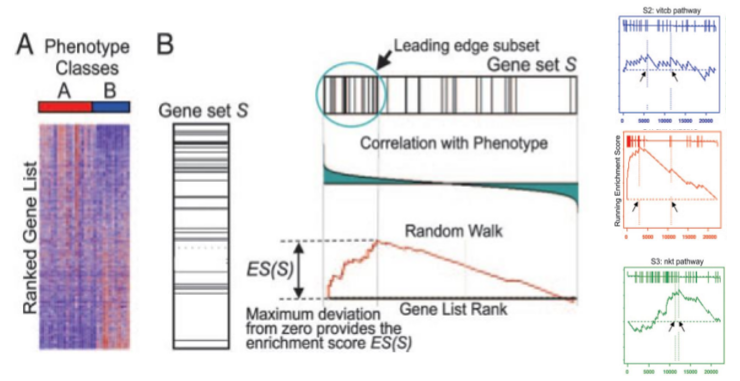
Rooted in the Gene Set Enrichment Analysis (GSEA) method developed to overcome ORA limitations.

The GSEA tests
If the distribution of the running sum doesn’t differ from a random walk then the list can be declared significantly enriched in that set.
Original test was a Kolmogorov-Smirnov test (K-S test) statistic with P-values computed by randomization.
![]()
PWA for untargeted studies
What to do when you don’t know what the metabolites ions are?
Most popular option is Mummichog (Li et al. 2013).

Mummichog change of approach
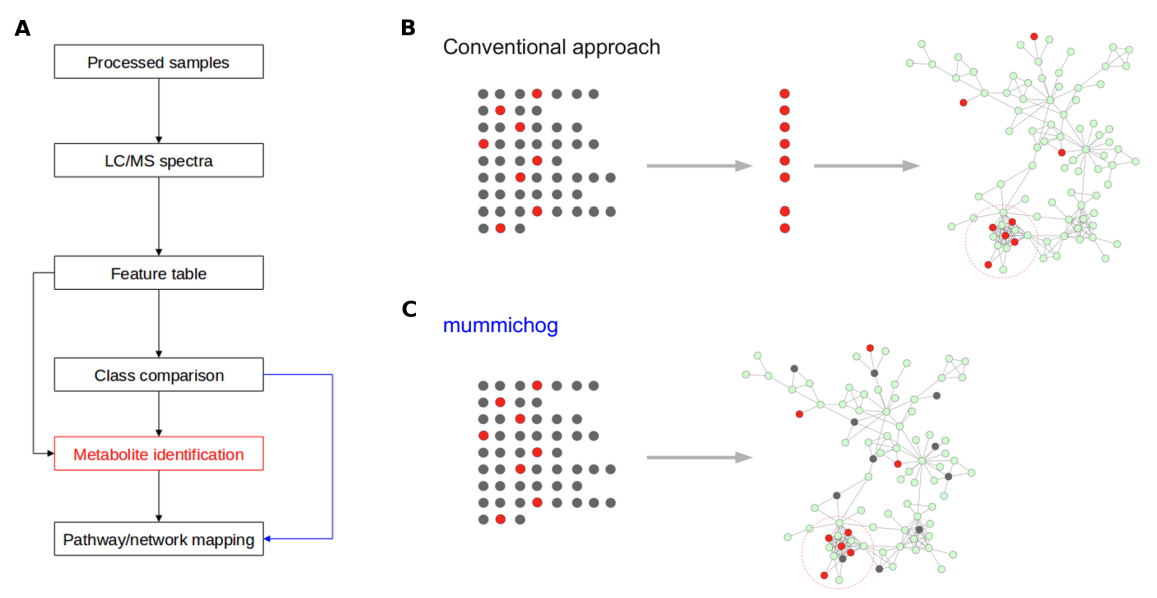
Mummichog redefines the work flow of untargeted metabolomics
Hypothesis Tests Decision Table
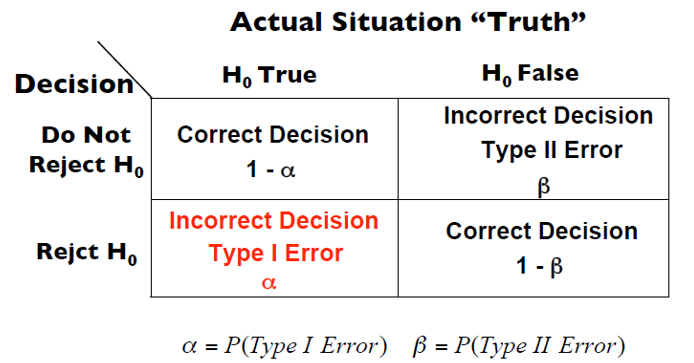
In a test with a null and an alternative hypothesis there are 2 possible right decisions and two possible incorrect ones (Type I and Type II errors)
Why Multiple testing matters

TYpe I error not useful here
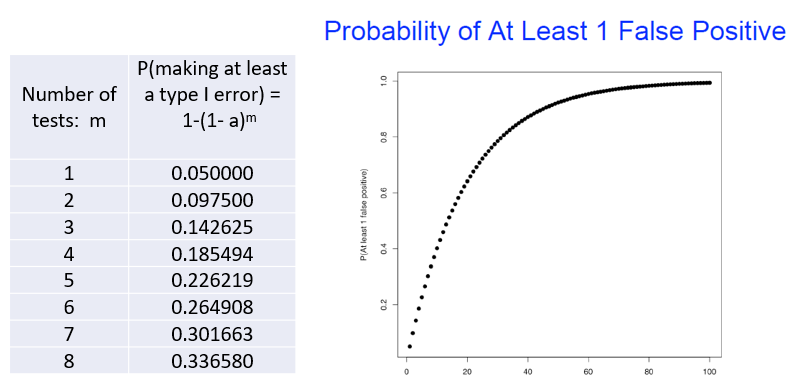
How to deal with this issue?

Some limitations
Incomplete Pathway Databases
Metabolite Misidentification
Chemical Bias of Assays
Background Set Selection
Selection of Compounds of Interest
Multiple testing issues

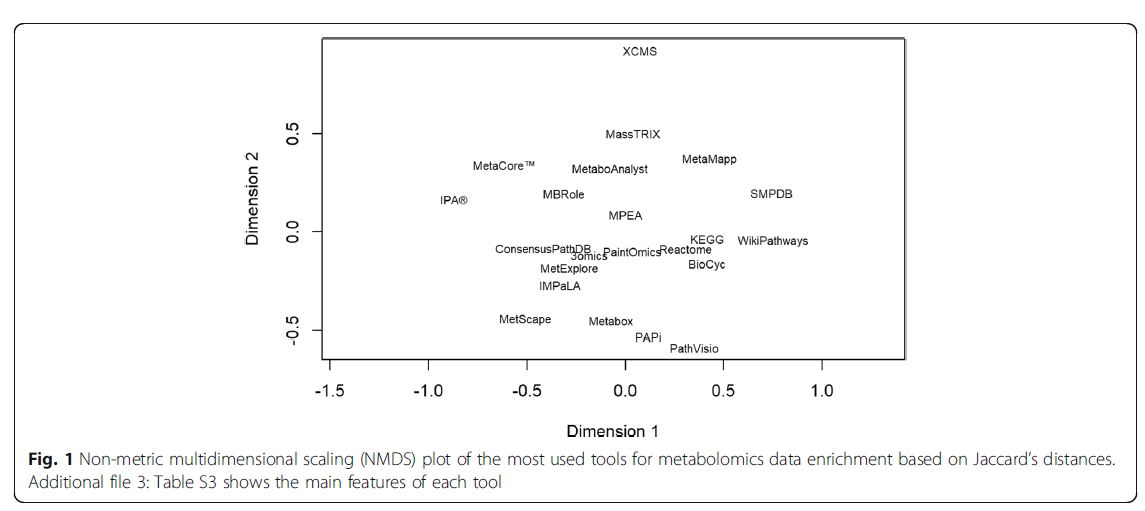
PAthway Analysis Tools
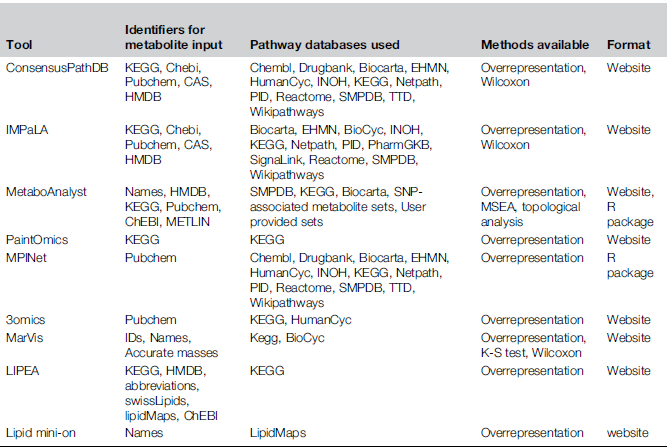
A comparison of tools
The space of tools (in 2017)